Базовые команды Python3
Здесь и далее:
x, y — объект, некая переменная,
x1/x2/x3/… — возможные варианты объявления чего-либо (в качестве подсказки для доп. понимания как эта конструкция может работать).
Типы данных
isinstance (x, str/int/bool/…) — определение типов данных.
callable (x/len/callable/…) — определение является ли аргумент вызываемым (является ли он функцией).
Проверка соответствия типу данных:
if not type(X) is str:
quit()
Фича с делением

Операции со строками
- upper() — преобразование в заглавные буквы
- lower() — в маленькие буквы
- capitalize() — Первая буква заглавная, другие — строчные
- replace() — замена строки. в строке
- title() — каждое предложение — с заглавной буквы
- dir(‘man’) — покажет все методы, которые можно сделать со строковым объектом.
- encode() — преобразование строки в байты
- startswith() — проверка начинается ли строка на нужный набор символов (вернется true/false)
- endwith() — проверка заканчивается ли строка на нужный набор символов
- find() — определение позиции нужной подстроки в строке
- » in url — есть ли вхождение нужного набора символов в строке
- help(‘google’.expandtabs) — покажет помощь о данном методе данного объекта (если появляется окно справки, в котором в конце окна терминала спрашиваются доп. команды, из него можно выйти с помощью нажатия клавиши q)
- strip() — удаление пробелов слева и справа у строки,
- lstrip(), rstrip() — удаление пробелов слева и справа у строки
- len() — подсчет числа символов в строке
- текст можно писать в несколько строк, используя тройные одиночные кавычки »’
- X.count(‘Y’) — подсчет числа вхождений подстроки ‘Y’ в строке X.



- split() — разделение строки на части массива по разделителю пробел
- join() — сцепление элементов списка с нужным разделителем

Форматирование строк
- f’текст{X}текст’ — форматирование строки с использованием переменной. Работает с версии Python 3.6 и выше.
- ‘текст %s текст’ % X
- ‘текст {} текст’.format(X)
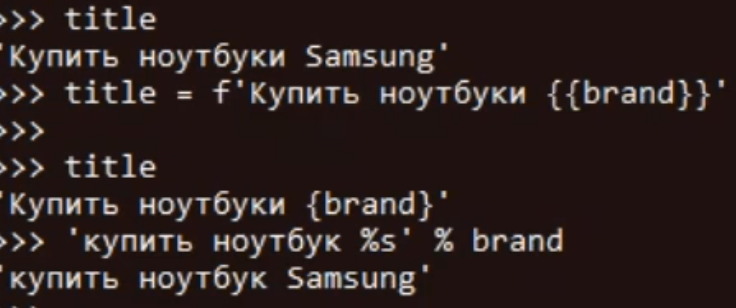
- r»текст с спецсимволами» — выводит текст с отображением всех спецсимволов (обычно используется для работы с регулярными выражениями):

Фичи работы с булевыми данными
- and() — замена условию перечислений and, возвращает True, когда ВСЕ элементы списка соответствуют условию.
- any() — возвращает True, когда хотя бы 1 элемент списка соответствует условию.

Другие полезные функции
range(X1, X2, Х3) — генерирует массив данных от Х1 до Х2 с шагом Х3.
input(‘Введите Х:’) — запрашивание информации у пользователя.
Вывод
print (‘something {} calling {}’.format(‘is’, 457)) — форматирование текста
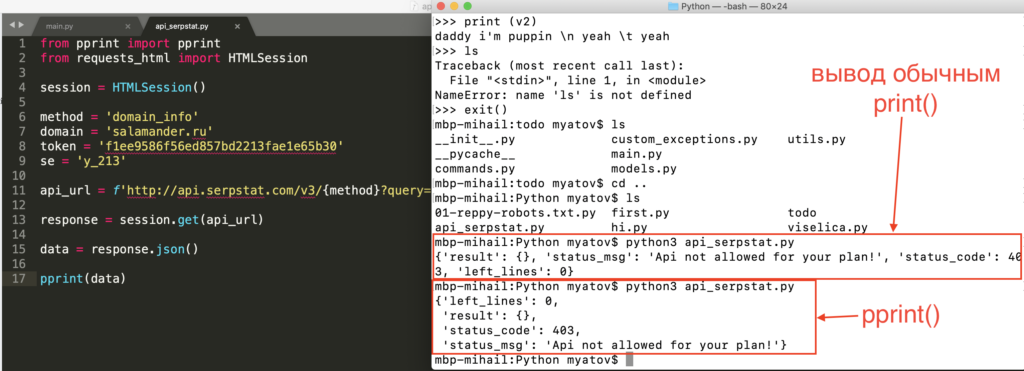
dir(x) — просмотр всех характеристик переменной, аналог print_r
pprint — модуль для более удобного чтения вывода из консоли.
Списки и Справочники
list.append(‘z’) — добавить к концу списка
list.insert(X, ‘z’) — добавить в нужное место списка (X=0 — в начало списка)
list.pop[0] — удаление значения с индексом 0
list.remove(‘value’) — удаление первого встречающегося слева значения ‘value’
dict.update({x: ‘x’}) — обновить ключ и значение справочника
dict.pop(x) — удаление ключа
dict.get(x) — взять значение справочника без получения ошибки в случае не существования ключа
dict.keys() — получение всех ключей
dict.values() — получение всех значений
dict.items() — получение всех ключей и значений (for key, value in s.items():)

print (‘some_string’ [0:5]) — выведет some_ — слайс.
- f = [5, 2, 3, 4]
- print (f[0:0+2]) — выведет 5, 2.
- print (f.index[‘5’]) — выведет 0 — номер индекса от начала справочника.
- а[-1] = EMPTY_MARK — вместо цифры 4 будет пустая ячейка.
- f[0], f[1] = f[1], f[0] — f [2, 5, 3, 4] — перемена индексов массива местами.
enumerate(x) — возврат индекса списка:

Множества
Создан для математических операций над множествами объектов.
В множество нельзя добавить повторяющиеся значения — все значения множества всегда уникальны.
При этом элементы внутри множества хранятся в неупорядоченном виде, и какой порядок будет внутри — программисту неизвестно.
set = {x1,x2,…}
type(s)
dir (set)
- s1 — s2 | Можно вычитать одно множество из другого
- s1.union (s2) | Объединение множеств
- s1 and s2 | s1 or s2 | И т.д. — можно делать логические операции

Примеры использования:
- есть база ключевых слов, из которой нужно убрать ряд ключевых слов.
- есть урлы сайта
Циклы
For, While.
Особенность:
- continue — остановка обработки всего кода ниже в цикле, и переход на следующую итерацию цикла
- break — принудительная остановка дальнейшей работы цикла.
Отлов ошибок
try:
10 / 0 #ZeroDivisionError
int('q') #ValueError
10 / 's' #TypeError
raise ValueError() #принудительно вызываем ошибку
except ZeroDivisionError as e:
print ('/0', e)
except ValueError:
print ('Wrong Value!')
except: #отлов любой ошибки
print ('Error')
else: #если ошибок не было
print ('Everything is ok!')
finally: #выводится всегда, как в случае наличия, так и в случае отсутствия ошибок
print ("I'll be back.")
Функции
Функции выполняются интерпретатором только в момент вызова.
При этом у функции — своя область видимости, т.е. находящиеся в ней переменные доступны только в рамках этой функции, и после выполнения функции сразу уничтожаются.
def function1 (input_x, input_y=5):
print (input_x, input_y)
return input_x + input_y
sum = function1 (2)


При этом при передаче дефолтных значений переменные с дефолтными значениями приема должны располагаться в самом конце списка приема, именно поэтому function X (x=5, y) — вызовет ошибку..
Функциональное программирование — это написание программного кода с чистыми функциями (функциями, которые не имеют никаких побочных эффектов). Примеры таких языков — хаски, лисп, элексир и пр.
Python — объекту-ориентированный язык программирования. Функция — это тоже объект.
Функции могут читать объявленные глобальные переменные, но не могут их переписать. Исключение — если внутри функции перед изменением глобальной переменной её вызвать как global var, что нарушает безопасность кода.
Глобальные переменные принято писать большими буквами.
Функции могут быть запущены и в одну строку:
#1й вариант:
def sum (a, b):
c = a + b
return c
#2й вариант:
sum = lambda a, b: a + b
Распаковка элементов списка
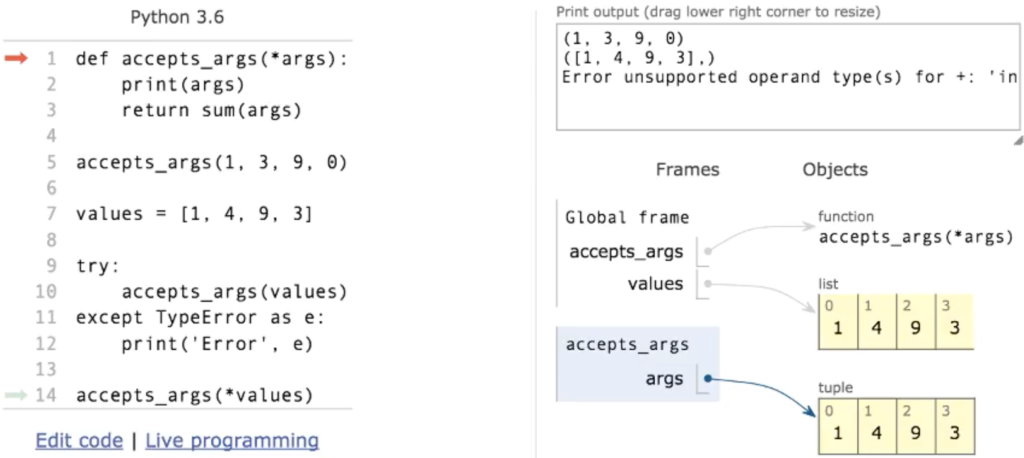
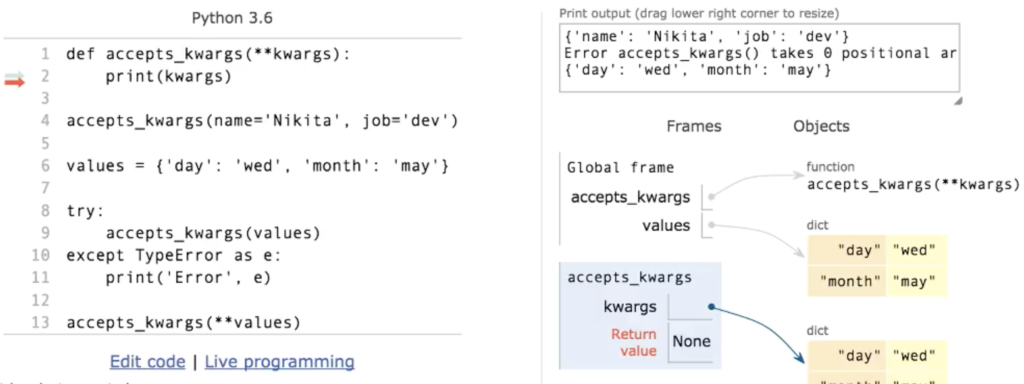
- def maximum_func (*values) — принимает несколько переменных tuple — например:
- maximum_func (1, 3, 5)
- но если будет передан список, то функция примет уже tuple, в котором первое значение будет списком:
- values = [1,2,3]
- Для передачи корректным образом следует использовать формат вида: maximum_func(*values)
Классы
Класс — это структура данных, объединяющая одинаковые объекты.
Названия классов принято писать с большой буквы. Названия функций — с маленькой.
Переменные в классе называются атрибуты класса (поля).
Объявленные внутри класса функции называются методами.
Если переменной присваивается класс, она носит название объект.
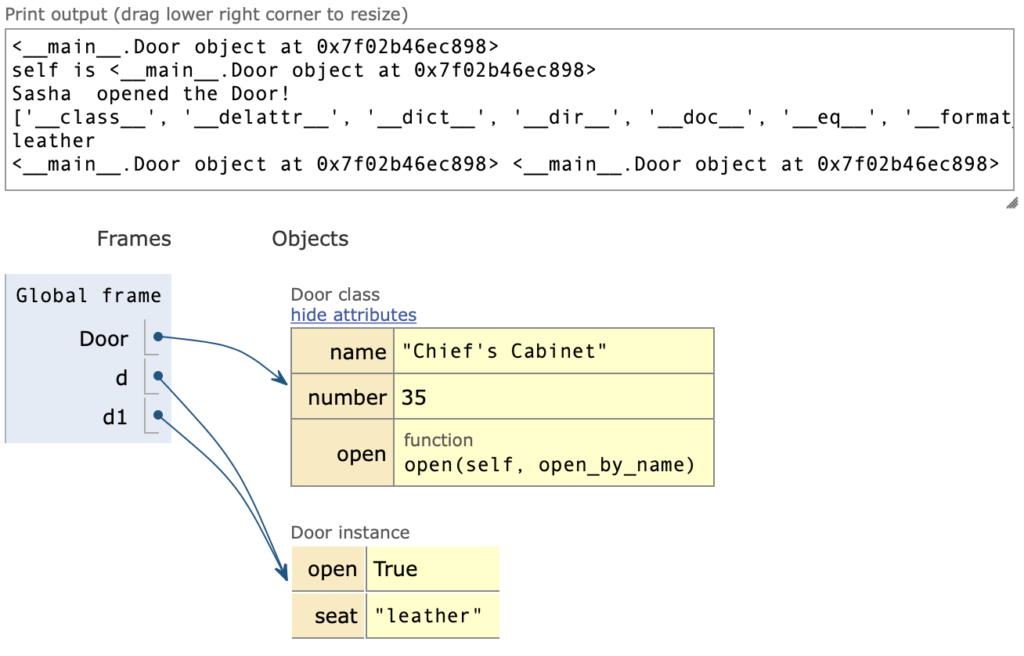
class Door: #фабрика дверей
name = "Chief's Cabinet"
number = 35
def open(self, open_by_name): #self is the objectprint('self is', self)print(open_by_name, ' opened the Door!')self.open = True
d = Door() #одну дверь купили домой
print (d)
d.open('Sasha') # equals d.open(self = d), открытие купленной двери
d1 = d
d.seat = 'leather' #ввели необъявленную в классе переменную
print (dir(d))
print (d1.seat)
print (d, d1) #2 разных имени для одного и того же объекта
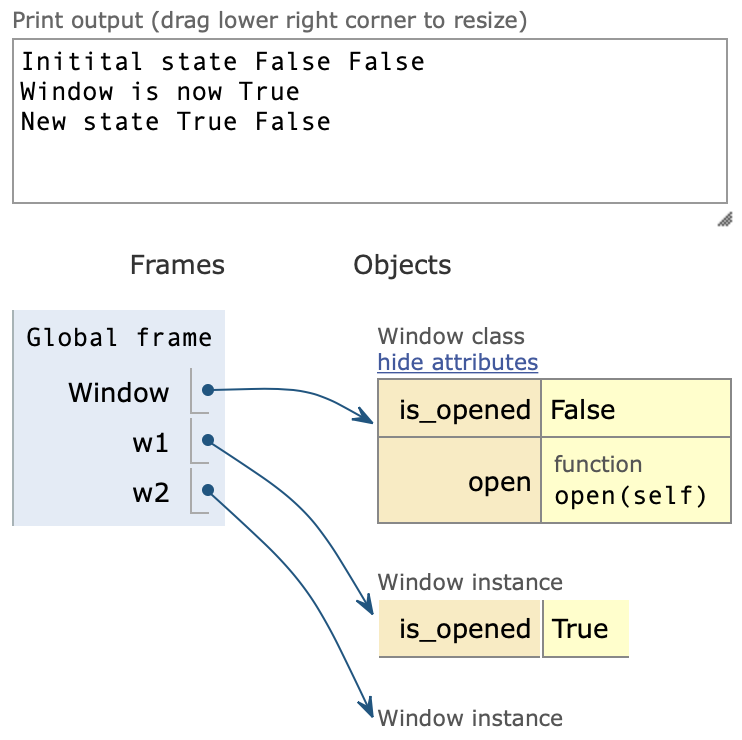
class Window:
is_opened = False
def open(self):
self.is_opened = not self.is_opened
print('Window is now', self.is_opened)
w1 = Window()
w2 = Window()
print ('Initital state', w1.is_opened, w2.is_opened)
w1.open()
print ('New state', w1.is_opened, w2.is_opened)
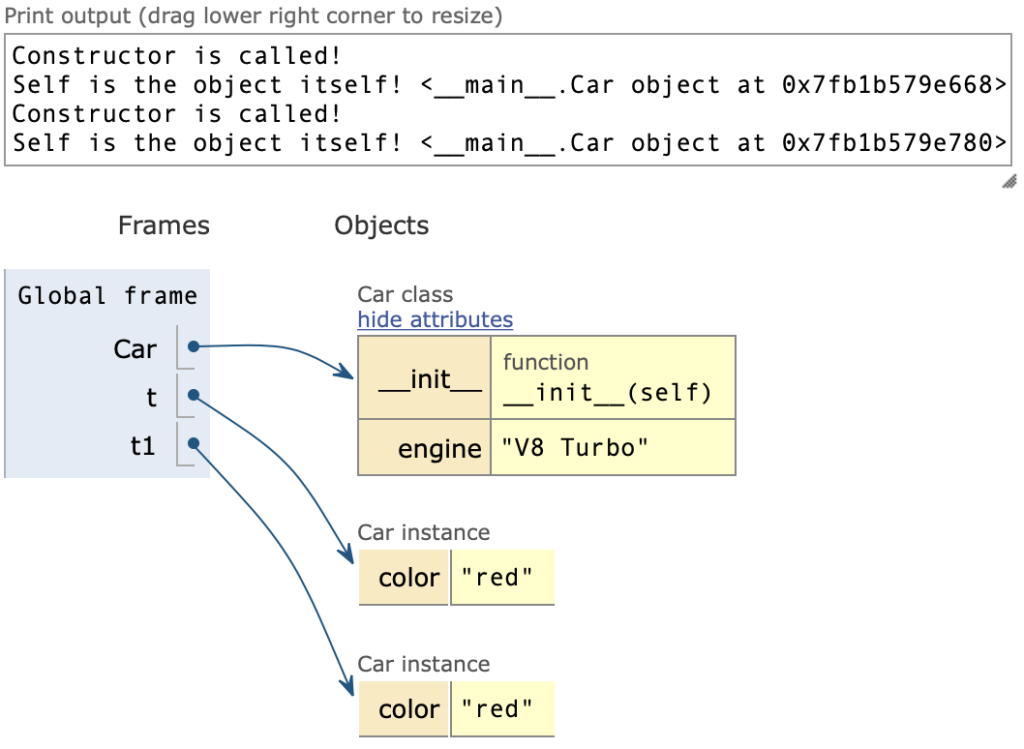
Конструктор
Это такой метод, который вызывается тогда, когда мы создаем экземпляр класса.
class Car:
engine = 'V8 Turbo'
def init(self):
print ('Constructor is called!')
print ('Self is the object itself!', self)
self.color = 'red'
t = Car()
t1 = Car()
1. Наследование
Наследование позволяет переиспользовать тот код, который уже есть, что делает разработку быстрее.
То есть новый класс может забирать все методы и поля родительского класса.
class Parent(object): #object можно не писать
def __init__ (self):
print('Parent inited')
self.value = 'Parent'
def do (self):print ('Parent do(): {}'.format(self.value))
class Child(Parent):
def __init__(self):
print('Child inited')
self.value = 'Child'
parent = Parent()
parent.do()
child = Child()
child.do()

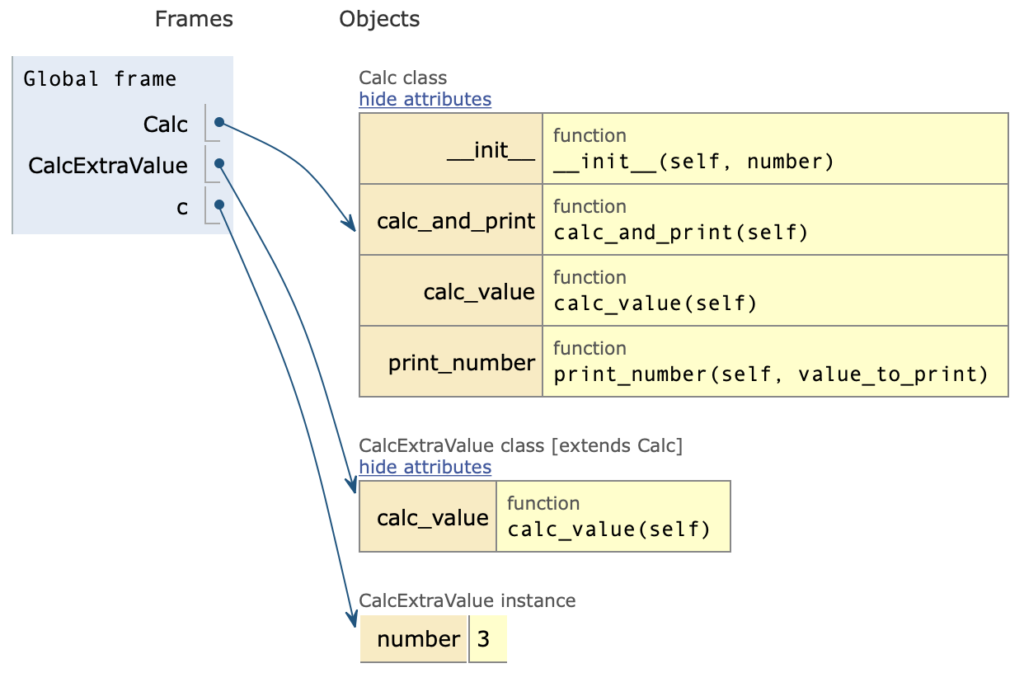
Переопределение
class Calc(object):
def __init__ (self, number):
self.number = number
def calc_and_print (self):value = self.calc_value()self.print_number (value)def calc_value(self):return self.number * 10 + 2def print_number (self, value_to_print):print ('------')print ('Number is', value_to_print)print ('------')
class CalcExtraValue(Calc):
def calc_value(self):
return self.number - 100
c = CalcExtraValue(3)
c.calc_and_print
2. Инкапсуляция
Позволяет скрывать реализацию методов, что делает их использование намного удобнее и безопаснее для конечного разработчика.
class Example(object):
def __init__ (self):
self.a = 1 #можно использовать везде где захотим
self._b = 2 #внутренние переменные, лучше извне не вызывать
self.__c = 3 #недоступна для использования извне
print ('{} {} {}'.format(self.a, self._b, self.__c))
def call (self):print ('Called!')
example = Example()
print (example.a)
print (example._b)
try:
print (example.__c)
except AttributeError as ex:
print (ex)
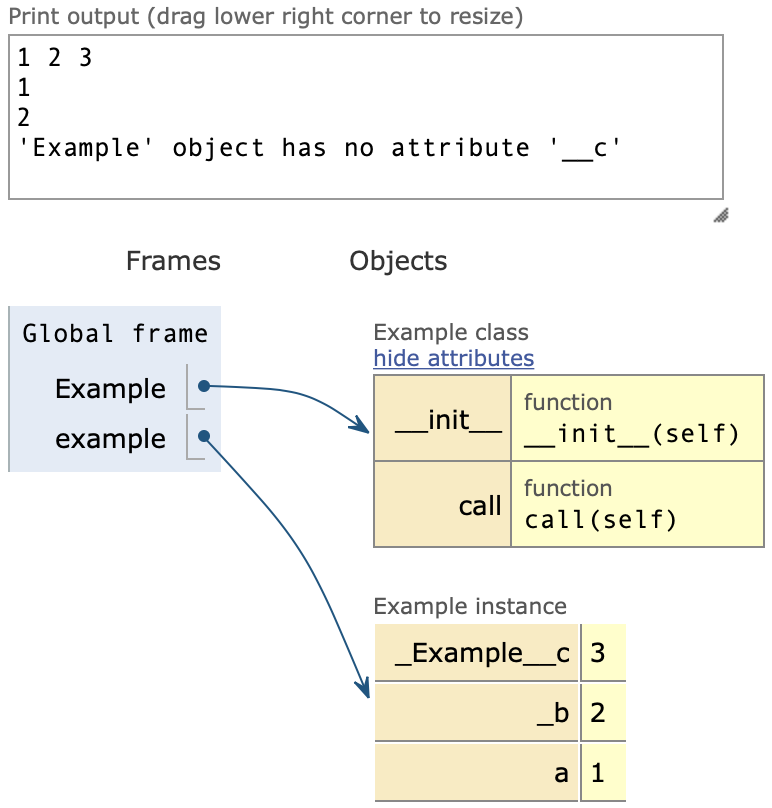
Методы классов, начинающихся с нижнего подчеркивания (_name) являются внутренними функциями.
Методы классов, начинающихся с двух нижних подчеркиваний (__name) отличаются тем, что при наследовании таких классов будет происходить мэнглинг (mangling), делающий еще более приватным метод класса, не давая переопределить его значение.
3. Полиморфизм
Позволяет использовать функции по разному, вне зависимости от типа их параметров.
class Parent(object):
def call(self):
print ('parent')
class Child (Parent):
def call(self):
print ('child')
class Example(object):
def call(self):
print ('Ex')
def call_obj(obj):
obj.call() #принимает любой объект, у которого есть метод call
call_obj(Child())
call_obj(Parent())
4. Абстракция
Позволяет упрощать сложные задачи, создавая небольшие классы для решения простых задач.
В каких случаях следует однозначно использовать классы?
- если в коде есть слово global у одной из переменных
- когда в коде есть классы, и нужно часть их функционала переписать
- в случае когда нужно написать что-то расширяемое, более универсальное решение
Super()
Позволяет обращаться к методам родителей.
className.__mro__ — показывает очередность наследования класса, особенно полезно — если у него есть несколько родителей:
mro = method resolution object

Если метод присутствует под одним и тем же именем в разных наследуемых классах, при его вызове будет вызван метод самого дочернего класса.
Вынос кода в разные файлы
Каждый Python-файл по сути является модулем. Всё, что в нём есть, может быть прочитано и импортировано.
При запуске кода подключаются интерпретатором стандартные модули, идущие с Python, такая папка называется служебной.
Папка с запускаемым скриптом также становится служебной для интерпретатора, и из нее все файлы также могут быть импортированы без дополнительного указания путей нахождения модулей.
Импортировать принято нужные модули в каждом подключаемом файле. Да, иногда может быть повторный вызов одного и то же модуля в разных подключаемых файлах, но на производительность это не влияет, т.к. интерпретатор вызовет модуль лишь 1 раз вне зависимости от числа вызовов этого модуля.
Все модули стандартной сборки перечислены здесь.
Также, можно вызвать весь модуль, по суть превратив его в объект:
import some_file
var1 = some_file.some_function()
var2 = some_file.some_var
from pprint import pprint as pp #можем переобъявлять импортированное
pp(var1)
from x_file import * #проимпортировать вообще всё что есть
Если нам нужно импортировать скрипт, лежащий в подпапке:
- создаем подпапку с нужным скриптом
- в подпапке (some_folder) создаем пустой файл __init__.py
- импортировать скрипт: from some_folder import some_script
- обращаться к скрипту как к объекту: some_script.some_function()
- или импортировать как from some_folder.some_script import some_function(), и обращаться уже к функции напрямую.
if __name__ == ‘main’: #обрабатываться код будет только в случае, если файл НЕ вызван сторонним файлом.
Работа с файлами
my_file = open (‘PATH_TO_FILE’, ‘MODE’, encoding=’cp1251′)
my_file.close() #рекомендуется закрывать файлы
Encoding = опциональный параметр, по умолчанию = UTF-8.
MODE = опциональный параметр, по умолчанию = чтение:
- r — read (чтение)
- w — write (запись); всё содержимое файла будет стерто при открытии.
- r+ — чтение + запись
- a — append (добавление в конец)
- rb — побайтовое чтение
- wb — побайтовая запись
- wa — побайтовый append
При открытии файла курсор интерпретатора ставится в 0 позицию, в самое начало файла. После операции по чтению содержимого файла курсор ставится в конец файла.
- my_file.tell() #узнать текущую позицию курсора
- my_file.readline() #считывание строки, на которой стоит курсор
- my_file.readlines() #считывание всех строк файла в список с разделителем \n.
Чтение больших файлов осуществляется с помощью цикла, т.к. такой функционал работает в качестве генератора, записывая каждую отдельную строку в память (в отличие от остальных методов чтения файла, когда весь файл загружается целиком в память компьютера):
for line in my_file:
print (line)
Но есть более удобный формат открытия и закрытия файлов, с помощью with:
with open('FILENAME', 'MODE') as my_file:
for domain in domains:
my_file.write(domain + '\n')
Для чего нужна побайтовая запись? Для работы с не текстовыми форматами. Например, с картинками:
image_url = 'https://previews-codecanyon.imgix.net/files/92185374/large.png?auto=compress%2Cformat&fit=crop&crop=top&w=590&h=300&s=ac4e862ec4c0aa3112a2890f7d82b554'
resp = session.get(image_url)
with open('image.png', 'wb') as my_file:
my_file.write(resp.content)
print ('Downloaded!')
Для работы с csv в Python есть встроенная библиотека csv. Можно работать через неё, а можно — через работу с текстовыми файлами.
#запись нескольких значений в csv:
with open('links.csv', 'w') as my_file:
for position, domain in enumerate(domains, 1):
my_file.write(f'{domain}\t{position}\n')
#чтение нескольких значений из csv:
with open('links.csv', 'r') as my_file:
for line in my_file:
data = line.strip().split('\t')
domain = data[0]
position = data[1]
print (domain, position)
Сериализация в Dump и Json
Сериализация — это сохранение словаря в файл, с последующим открытием данных файла сразу в словарь.
В Python встроено 2 библиотеки, которые позволяют делать дампы памяти в файл, с возможностью последующих импортов — это Dump & Json.
Dump:
- делает читаемые только в Python файлы (в основном для записи служебной информации),
- конвертирует данные в байты,
- иногда дампы могут даже заменить базы данных,
- может работать с данными различного вида
Json:
- делает читаемые в том числе людьми и браузерами файлы,
- конвертирует данные в строку,
- используется например в случае, когда нужно передавать данные в фронтенд специалисту по JavaScript в json формате,
- работает только с данными вида словарь.
Работа с операционной системой
Модуль OS, встроенный в интерпретатор, призван для выполнения действий с самой операционной системой:
- посмотреть переменные окружения (os.environ),
- получить полный путь к текущей папке (os.getcwd()),
- создать/удалить файл,
- посмотреть содержимое папки (os.listdir()) или создать её,
- посмотреть число файлов в папке,
- посмотреть все файлы и подпапки в какой-то папке (os.walk(‘path’))
- и очень много других методов.
Пример кода, который загружает содержимое всех файлов .py в надпапке:
import os
my_folder = os.getcwd() #определяем путь до текущей папки
folders = my_folder.split('/')[:-1] #разбиваем строку с папками на слова по разделителю /, берем слайс с 1 по предпоследний элемент
upper_folder = '/'.join(folders) #склеиваем строку с папками - с рутовой до выше стоящей над текущей
for filename in os.listdir(upper_folder): #берем список всех файлов и папок в вышестоящей папке
if '.py' not in filename: #берем только файлы с расширением .pycontinuefile_path = upper_folder + '/' + filename #получаю полный путь к файлуwith open(file_path, 'r') as file:code = file.read()print (code)
Базы данных
Это система управления набором файлов или документов, хранящихся определенным методом в определенном месте.
Данные хранят в виде таблиц, которые могут быть взаимосвязанными (реляционными). Зачастую они поддерживают язык SQL для работы с данными. Относительно медленные из-за постоянных операций чтения и записи на диск. MySQL, PostgreSQL, SQLite.
Другая разновидность баз данных — документные (noSQL), которые хранят данные в разных видах: «ключ:значение — Redis», «ключ:json — MongoDB», «графы — OrientDB» и т.д.
Для работы с SQL базами в Python есть специальные библиотеки. А есть — сторонние системы ORM (object relational mapping, которые работают без «голого» SQL), мы же рассмотрим модуль sqlalchemy.
Использовать можно софт для визуализации работы с СУБД можно например Valentino Studio (бесплатно распространяется под MacOS, Linux и Windows).
import sqlalchemy as sa #ORM - система работы с базой данных без использования голового SQL
metadata = sa.MetaData()
connection = {'user': 'USERNAME', 'database': 'DB_NAME', 'host': 'HOST_NAME', 'password': 'PASS_NAME'}
dsn = 'postgresql://{user}:{password}@{host}/{database}'.format(**connection)
Book = sa.Table( #создаем таблицу
'books', metadata,
sa.Column('id', sa.Integer, primary_key = True), # первичный ключ, ускоряет индексацию
sa.Column('original_id', sa.Integer),
sa.Column('name', sa.String(255)),
sa.Column('description', sa.Text),
sa.Column('book_details', sa.Text),
sa.Column('comments', sa.Text),
sa.Column('pages_num', sa.Integer),
sa.Column('genres', sa.String(255)),
sa.Column('alias', sa.String(255)),
sa.Column('image', sa.String(255)),
sa.Column('date', sa.Date),
sa.Column('processed', sa.Boolean)
)
if name == 'main':
engine = sa.create_engine(dsn)
#metadata.drop_all(engine)
metadata.create_all(engine)
Работа с API
Всегда прежде чем использовать АПИ следует читать инструкцию.
Если API работает с Get-запросами, то можно получать результаты работы API через браузер.
IPython
ipython (так и следует писать в консоли) — Interactive Python.
Многопоточность
Поток выполнения (thread — нить) — наименьшая единица обработки, исполнение которой может быть назначено ядром операционной системы. Поток при этом находится внутри процесса.
Несколько потоков могут существовать в рамках одного процесса.
Потоки выполнения разделяют функции процесса (его код) и его контекст (значения переменных, которые они имеют в любой момент времени).
Процесс — можно запустить, убить и пр. Процесс имеет своё id в операционной системе.
- Поток — входит исключительно в состав процессов. Есть ограничения в операционной системе относительно числа одновременно запущенных потоков.
- В один момент времени выполняется только 1 поток для одного ядра процессора.
- Потоки не эффективны для сложных вычислений (для этого нужны модули на С).
За многопоточность в Python отвечает модуль threading.
from threading import Thread
def worker1():
while True:
print ('Thread1 working')
thread1 = Thread(target=worker1)
thread1.start()
def worker2():
while True:
print ('22222')
thread2 = Thread(target=worker2)
thread2.start()
Когда потоки работают с одним и тем же ресурсом, например, пишут в файл, могут быть накладки и непорядок. Для случаев, когда результаты многопоточной работы требуется сложить в упорядоченном виде, предусмотрены блокировки потоков.
Для работы с очередью потоков хорошо подходит модуль queue (тип данных = очередь).
- когда какой-то поток работает с очередью, другие ждут.
- запись в очередь и получение очереди быстрее.
from concurrent.futures import ThreadPoolExecutor
def work1():
for i in range(10):
print (f'Thread 111 is working {i}')
def work2():
for i in range(10):
print (f'Thread 222 is working {i}')
executor = ThreadPoolExecutor (max_workers = 10)
executor.submit(work1) # запустили 1й поток
executor.submit(work2) # запустили 2й поток
for i in range (20, 30): # запустили 3й поток
print (i)
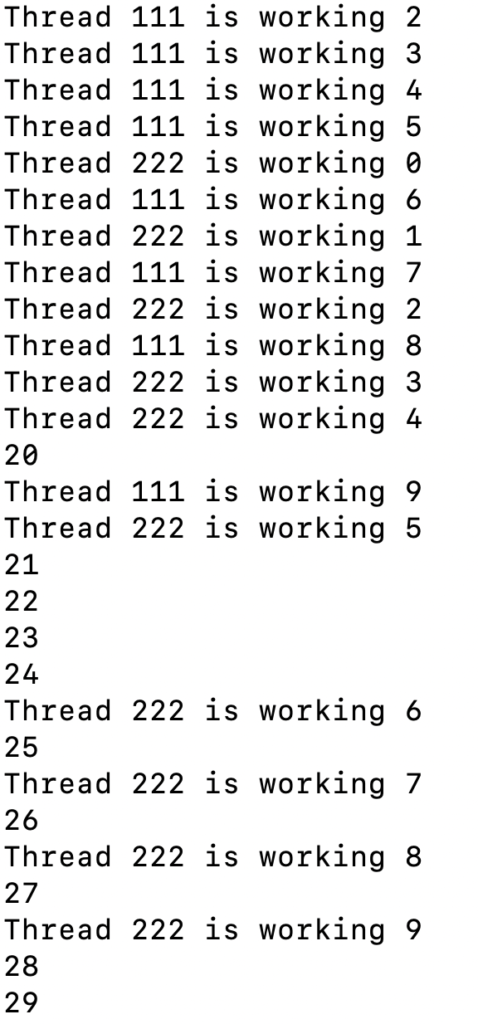
Так как многопоточность — это условная величина (все потоки обрабатываются не параллельно, а последовательно компьютером, с минимальным переключением по времени), зачастую имеет смысл внедрять многопоточность, если в порядке работы имеет место быть ожидание другого сайта.
Сложность работы с потоками заключается в сложности синхронизации данных между потоками. В случаях, когда скрипт спарсил страницу, нашел на ней Х ссылок, и есть необходимость пустить Х в несколько потоков, используется тип данных Очередь.
Скрипт парсинга всех страниц сайта в несколько потоков:
import random
from requests_html import HTMLSession
from concurrent.futures import ThreadPoolExecutor
from queue import Queue
scaned_urls = {}
def worker(queue):
session = HTMLSession()
while queue.qsize() > 0:
try:
url = queue.get()
print ('Send request to', url)
#если поставить timeout=2, то по сути устроим ДДОс сайта, - программа будет отправлять каждые 2 сексунды 10 запросов.
#сервер не успевает отвечать за 2 секунды, поэтому тайтл уже не пишется.
resp = session.get(url, timeout=10) #timeout = 30 секунд по умолчанию. Если ответ не приходит - ошибка.
print (resp.html.xpath('//title/text()')[0])
all_links = resp.html.absolute_links
for u in all_links:
if u in scaned_urls:
continue
else:
queue.put(u)
scaned_urls.add(u)
except:
pass
def main():
qu = Queue()
url = 'http://myatov.ru/news/'
session = HTMLSession()
resp = session.get(url)
for u in resp.html.absolute_links: #собираем все ссылки со страницыqu.put(u)print ('Queue size', qu.qsize())with ThreadPoolExecutor(max_workers=10) as ex:for _ in range(10): #запускаем в 10 потоковex.submit(worker, qu)#ex.map во многих случаях может облегчить жизнь
main()
Многопоточность лучше вызывать из функций, в рамках которой работать с методами классов.
Обучающее видео Python
Продублировал всю информацию выше о Пайтоне в обучающий видео ролик.